

User Guide
Node Drain Agent Guide
Overview
Node Drain Agent is a feature that saves time and effort for operations for node drain, such as cluster upgrades. With this feature, you can check the status of nodes and pods to be drained in advance via the CLI (cnatix command). If there are no problems, Node Drain Agent marks target nodes unschedulable and evicts pods safely.
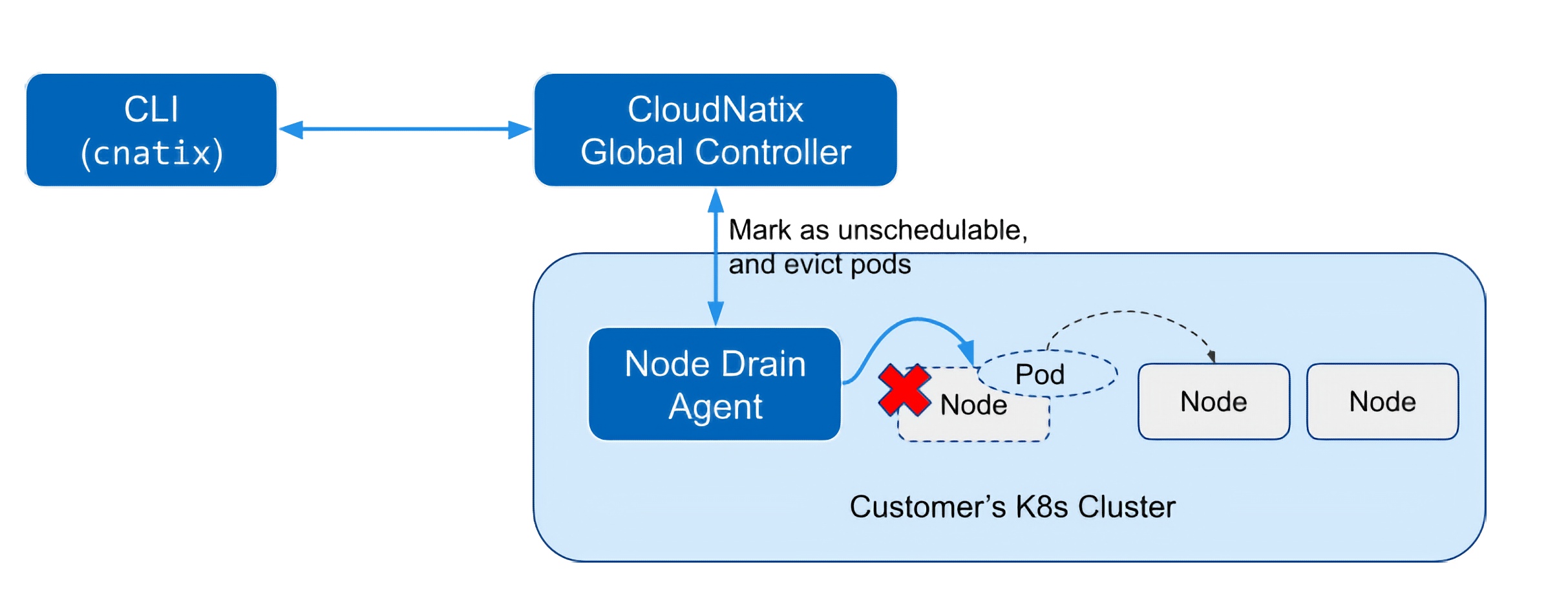
This agent supports not only the same functionality as the kubectl drain command, but also interactive commands for draining, pre-checking of pods with strict PDBs that block eviction, reporting of pre-checks, etc.
Enabling Node Drain Agent
The Node Drain Agent feature is not enabled by default. To enable the feature, you need to take the following steps:
- Upgrade CCOperator to the latest version. Specify Node Drain Agent related parameters in
values.yaml. - Add
cluster-rightscaler-agentto the list of Cluster Controller components that are installed in the cluster.
To upgrade CCOperator, you first need to pull the latest Helm chart (v0.566.0 or later).
helm repo add cloudnatix https://charts.cloudnatix.com
helm repo update
helm pull cloudnatix/ccoperator
Then set the CCOperator version and Node Drain Agent parameters for in values.yaml:
clusterRightscalerAgent:
nodeDrainAgent:
enable: true
Then the next step is to add cluster-rightscaler-agent to the list of Cluster Controller components. Here is an example command:
cnatix clusters components create \
--cluster <cluster-name> \
--kind cluster-rightscaler-agent \
--version <agent-version> (--upgradable)
The latest stable version of cluster-rightscaler-agent can be found here. When --upgradable is set, the component is auto-upgraded.
Drain nodes with CLI
You can drain nodes using cnatix k8s drain run command.
cnatix k8s drain run --cluster <cluster-name> [<node>...]
This command accepts multiple nodes to be drained, separated by spaces. You can also specify target nodes with a label selector if you set the --node-label-selector flag instead of the node argument.
Note: Node arguments and label selector cannot be used together.
The following is an example output of draining worker-node-1 in my-cluster. (Lines beginning with '#' are added for explanation. They are not output in the actual command.)
$ cnatix k8s drain run --cluster my-cluster worker-node-1
# (1) Ask for final confirmation before sending the drain request.
? Request node drain to worker-node-1? Yes
- Requesting node drain... done (uuid: e607dc7a-826d-4d7d-be9a-7df73f6c07b7)
- Preparing node drain (phase: PENDING)... done
- Waiting for node drain to be ready (phase: PENDING)... done
- Checking node drain can be run (phase: READY)... done
# (2) Report pods to be evicted that did not pass the pre-check.
X 13 eviction is blocked for the following reasons
Pods matching a strict PDB: [3]
- shopping/cart-5967dc5db7-7ll2k in node/worker-node-1: pod with strict PDB (DisruptionsAllowed=0)
- shopping/shop-57cc4b4bd7-2vx7z in node/worker-node-1: pod with strict PDB (DisruptionsAllowed=0)
- shopping/shop-57cc4b4bd7-5plbg in node/worker-node-1: pod with strict PDB (DisruptionsAllowed=0)
Pods are managed by DaemonSet: [4]
- shopping/ds-1-dp644 in node/worker-node-1:
- shopping/ds-2-cfb82 in node/worker-node-1:
- kube-system/fluentd-elasticsearch-sxpxv in node/worker-node-1:
- kube-system/kube-proxy-7kjh6 in node/worker-node-1:
Pods with a local storage: [2]
- shopping/local-storage-7d4d88bdc4-wfhlw in node/worker-node-1:
- shopping/prometheus-0 in node/worker-node-1:
# (3) Ask how to deal with pods that did not pass the pre-check.
? Cancel this node drain request? No, continue and choose how to resolve the above pods.
? How to handle "Pods matching a strict PDB"? skip
? How to handle "Pods are managed by DaemonSet"? skip
? How to handle "Pods with a local storage"? force_evict
- Requesting how to handle pod with filter errors... done
- Waiting for filter errors to be resolved (phase: IN_PROGRESS)... done
# (4) Display the eviction progress.
Pod Eviction Status:
✓ shopping/backend-68db66cb46-fx676 in node/worker-node-1 is evicted
✓ shopping/ui-67df8bfbc7-dhcdj in node/worker-node-1 is evicted
✓ shopping/backend-68db66cb46-qcgzj in node/worker-node-1 is evicted
✓ shopping/local-storage-7d4d88bdc4-wfhlw in node/worker-node-1 is evicted
✓ shopping/prometheus-0 in node/worker-node-1 is evicted
Request is SUCCEEDED
Running k8s drain run after a node draining request failed
When a node draining request fails, Node Drain Agent does not process a following drain request automatically. To process the request, you need to explicitly confirm the failure.
Here is an example failure of node drain requests as a specified node is not found in the cluster:
Request is FAILED: get nodes: nodes "ip-aaa-bbb-ccc-ddd.region.compute.internal" not found
Node Drain Agent stops processing new node draining requests (either queued or newly created) until the user explicitly tells it to proceed.
When you run the k8s drain run command in such a situation, you'll see a warning message as follows:
! Request is pending due to that the last completed request has failed
? Continue node drain request ignoring the last drain failure? (Y/n)
By answering yes to the prompt, you can force it to run the request.
Canceling a node draining request manually
A node draining request may be detached from the CLI due to an error. In such a case, please cancel the detached request manually.
To cancel a certain node draining request, run the k8s drain cancel command with the UUID of the node draining request specified.
To list node draining requests for your tenant including such a detached request, please use the k8s drain list command.
Marking nodes schedulable
The cnatix k8s schedulable create command can be used when you want to mark nodes as schedulable again. For example, you can run the command after node maintenance has been completed.
cnatix k8s schedulable create --cluster <cluster-name> [<node>...]
Like the drain run command, this command also accepts the --node-label-selector flag to specify nodes.